
| stapeliads.net :: | Home | Site map | Documents | Forum | PAN | SI Database | Contact us | Guide | About us |
| Fabio d'Alessi the stapeliads.net database the logic behind our database and the S.I. code Document Revision 1.0 First Edited October, 1st, 2005 Reads : 4445 |
Without entering into too much detail, genera and species
are the lower hierarchic levels in which botanists and
zoologists subdivide living beings, following a method
established by Linnaeus in his books (Species Plantarum,
Systema Naturae, etc.) in 1753-1759.
According to this method, animals, plants, bacteria and
every living being can be properly put in relationship
with the others following a pyramidal hierarchy of different
levels (top to bottom: Kingdom, Phylum, Class, Order, Family,
Genus and Species). Several variations of this method have
evolved in centuries, but the basic principle still
remains valid.
Unfortunately, according to the "weight" given to different
concepts and features, different authors can build (and
usually do) different hierarchies, with subtle, yet
sometimes incompatible differences from previous
classifications.
Because of this (as well as other reasons) in the centuries
hundreds of authors have published different descriptions,
articles, classifications, revisions and
counter-revisions of the same plants or animals, generating
an endless plethora of names, of which some are valid, others
are synonyms and others are regarded as invalid. In some
cases the nomenclature is evolving at such a pace that
it is not uncommon to find a plant with tens of names.
The confusion arising from this is clear.
This problem is present in the Stapeliad world as well,
and it is well evident since the very beginning when
some authors, talking about these plants, still put
them in a family Asclepiadaceae
while others, following a more recent approach, merge
them into the Apocynaceae family, and treat
asclepiads as the subfamily Asclepiadoideae.
It is probably not so wrong to say that every species
of asclepiad has been given at least two or three different
names in its botanical history.
Notwithstanding this, the "botanic names" of plants
prove to be an invaluable
resource to help people speaking different languages and
living in different countries refer to a specific plant,
therefore every tool or database dealing with stapeliads
has to take into account the existing scientific nomenclature,
with all its problems, synonims and neverending changes.
At the moment a very good resource that keeps track of
all published scientific plant names (as well as
the names of the authors that published them, and
the publication where they published it and when)
is the I.P.N.I.
(the International Plant Name Index).
stapeliads.net has a direct interface to the full
nomenclatural data present at IPNI, and heavily
refers to it.
After speaking about nomenclature, botanic names, genera and
species, let's briefly talk about another issue: entities.
You will find the word "entity" in the stapeliads.net database
and pages quite often. An "entity" is nothing magic, it is just a word we use to
refer to a single plant or group of plants with very high similarity
between them. It is not a species - the definition of "species"
is something so delicate and fought on that we do prefer to leave
that to hi-tec scientists, botanists and philosophers.
An entity is just a plant or group of plants with extreme
similarity and consistence among them.
Whenever you walk in habitat and stump into a population of plants,
you will see they display remarkable similarities in the stem,
growth, flower shape and colors. The population might be scattered
in a few mile area or spreading in a vast continuous area. We regard
this population as an "entity". If you then walk to a totally
different place, you might found
another group of plants of the same "species", but displaying
a different flower shape and color - a different entity.
An "entity" is not defined in a theoretical and philosophical
way - stapeliads.net tries to be extremely "practical", so
an "entity" is just a useful way to distinguish different
plants, even when they are the same species.
You can think at the SI code which you will find throughout
the whole stapeliads.net website as the "entity" code. I can't
remember if Loukie and I chose S.I. as an acronym for stapeliads.net
or for Specimen Id - possibly for both.
The stapeliads.net database is built around the two above ideas.
There is a nomenclature database keeping track of genera,
species, publications, dates and authors (in other words a
database of ideas), and there is a specimen database
with photographs, notes and observations of real plants in
habitat and cultivation (in other words a database of things).
The way a certain entity (material thing) is linked to a scientific
name (ideal concept) is the determination.
 |
 | |
| Entity (real plant) | Determination | Genus/Species (concept) |
Working on the schema we just described,
I have begun coding the stapeliads.net database in my
spare time between 2003 and 2004.
Initially the idea was to build a "photography" database,
like many around the net in these days. It became
immediately evident that if we were using a single
"photo" database, with a scientific name attached
to a photo, there would have been many problems with
synonyms, spelling errors and name changes.
Because of this I opted for a wider approach: I split
the "name" part from the "image" part - downloaded
the Asclepiadaceae data from IPNI
(authors, plant names, publication names and dates)
and arranged them in a "nomenclatural database", built
up a database of pictures and habitat/cultivation notes
(and arranged them in a "specimen database") and
then built up a set of "determinations" in order
to link this or that specimen to this or that
published plant name.
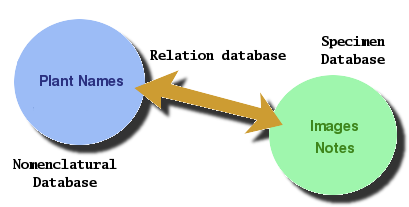
Simple, functional, sleek. But not
groundbreaking.
The database was doing what we wanted it to do : you
were looking for Stapelia gigantea and it was
reporting you the author abbreviated name, when it
was published and where - and it was displaying you
the photos of the specimens currently determined as
Stapelia gigantea.
Good. But... enough?
I started playing with the database while Loukie was
going on uploading pictures from South Africa to Italy
night after night and after a while it became evident
that "Stapelia L. (Sp.Pl.1753)" was not enough
for me. Stapelia what? Stapelia where?
Why Stapelia? - IPNI does not give these answers
since it focuses on pure nomenclature and publication
data, but these are quite common questions.
Notes on Genera and Species. The first thing
I did was to expand the nomenclatural database with two
additional note-tables, one for genera and one for
species and lower level
taxa (species, subspecies, forms, varieties and
so on). Table notes, strictly hand edited, contain
information not available on IPNI, as, for example,
distribution area, cultivation notes, historical
notes, name etymologies and so on. All these notes,
which add great detail to a taxonomical entry,
make up an "annotation database", linked to
the IPNI nomenclature backbone.
IPNI extension. And at the end, no, I didn't
like that "L." and that "Sp.Pl.". Yes, it's true -
everywhere in every book you find them - but - in
many many years I have never found a place where to
read author and publication names in their plain
full format. Sure we all know that that "L." stands
for Linnaeus, but I would like to know how many know
exactly what the "N" in N.E.Br. stands for, when he
lived and so on. This is why I reconnected to
IPNI and this time I downloaded the full set of data
on plant names, on the publications and their extensive
descriptions, on the plant authors, their full names
and dates. This greatly enlarged the Nomenclatural
Database.
Synonyms. One of the things that causes more
headaches to newbies (but not only) is keeping
track of valid names, invalid names and, especially,
synonyms according to the various authors (one
frequent scenario is this: author A uses
a valid species name; author B treats that as a
synonym for another species of the same genus;
author C cancels the whole genus as invalid - and
so on). IPNI keeps
track of only a minor part of
these synonyms. The remaining ones usually
are hidden at the end of monographies and books.
One of the tasks to be performed is building a
complex synonym index on stapeliads.net to be
embedded in the nomenclatural database.
-> As of
October 2005, this is the only part of the
structure which is not finished yet.
Reports. While the first three improvements
were mainly made to the nomenclatural database,
a fourth improvement was made to the entity database.
What I wanted was each entity contents to be not
only written by the site administrators, but I
wanted also to leave to the users, visitors,
botanists and enthusiasts an open door for their
own contributions: images, cultivation notes,
curiosities. This is where the concept of "report"
came from. A report is a set of notes (with or
without an image) attached to an entity. Notes
can be added by anyone and, this way, the general
knowledge about that single specimen is not something
statically put on the net by the authors of the
site but something growing with the contributions
of every user.
Field Numbers. Last, in the attempt to
concentrate as much information
as possible on each single entity, I also started
to code a "field number database" in which
further information about locality, collecting
data, habitat notes and other can be sent in.
This is how the database looks like now.
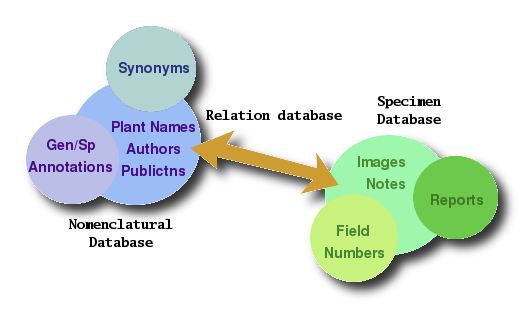
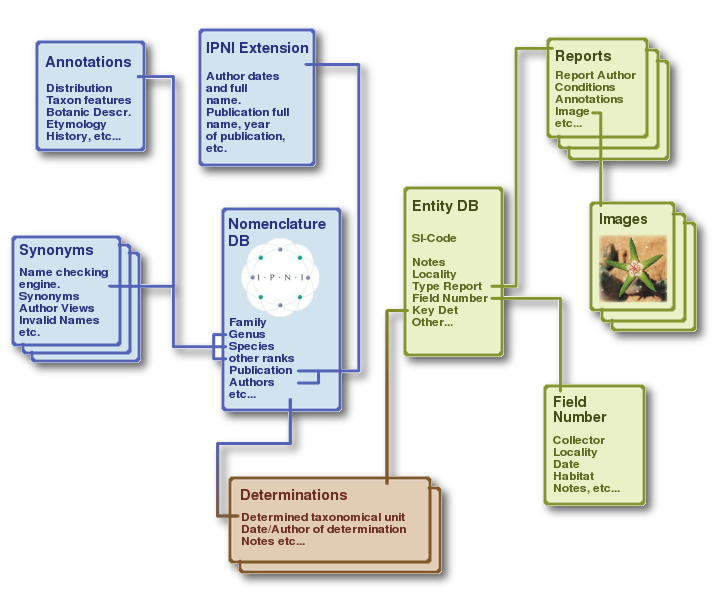
Given the huge amount of data and linking tables built one thing
that became evident playing with the second release of the
database was the need for more "ways" to access to the data.
The classical interface Loukie and I were using, infact, was
not enough - it was squeezing out only a minor part of the
new structure capability.
Because of this I tried building alternative ways to
access to the data contained in the stapeliads.net
server. Right now these are the tools which interface
with the stapeliads.net structure: